
Dogsheep: Personal analytics with Datasette
Datasette Weekly volume 2

This week’s newsletter will take a deep dive into Dogsheep, my project to build tools for personal analytics on top of Datasette and SQLite.
Dogsheep
The name requires some explanation. In February 2019 Stephen Wolfram published Seeking the Productive Life: Some Details of My Personal Infrastructure - an astonishingly detailed essay about the extreme lengths he has gone to over the years to optimize his personal productivity. Stephen runs a 1,000+ person company as a remote CEO, so he’s been figuring out productive remote working since long before Covid forced the rest of us to all learn to work from home.
There’s a lot of stuff in there, but one thing that stood out to me in particular was Stephen’s description of his “metasearcher”:
A critical part of my personal infrastructure is something that in effect dramatically extends my personal memory: my “metasearcher”. At the top of my personal homepage is a search box. Type in something like “rhinoceros elephant” and I’ll immediately find every email I’ve sent or received in the past 30 years in which that’s appeared, as well as every file on my machine, and every paper document in my archives.
That sounded pretty great to me, so I asked myself if I could bring all of my data from different sources together into a single personal search engine. And since I wanted to build something that was inspired by Wolfram but not nearly as impressive, I decided to call it Dogsheep.
Stephen has a search engine called Wolfram Alpha, so obviously my search engine would be called Dogsheep Beta. And I admit that this pun amused me so much I felt obliged to build the software!
Dogsheep is a collection of open source tools designed to convert personal data from different sources into SQLite databases, so that I can explore them with Datasette. The tools I’ve written so far are:
twitter-to-sqlite - your tweets, followers, people you follow, favourited tweets.
healthkit-to-sqlite - converts Apple HealthKit into tables about heart rate, workouts, step counts, running routes.
swarm-to-sqlite - checkin history from Foursquare Swarm.
inaturalist-to-sqlite - wildlife and plants you have spotted on iNaturalist
google-takeout-to-sqlite imports data from Google Takeout, which can include your Google Maps location history, your search history on Google and more.
genome-to-sqlite imports your genome from 23andMe into a SQLite database.
github-to-sqlite imports repositories you have created or starred on GitHub, plus issues, issue comments, releases, commits, dependent repos. Live demo here.
pocket-to-sqlite imports articles you have saved using Pocket
hacker-news-to-sqlite imports stories and comments posted to Hacker News
dogsheep-photos imports metadata about photos from Apple Photos, including machine learning labels. See Using SQL to find my best photo of a pelican according to Apple Photos.
evernote-to-sqlite (new this week) converts exported notes from Evernote into a SQLite database. See Building an Evernote to SQLite exporter for details of how I built that one.
These tools have inspired some other developers to build their own. Here are the other tools in the Dogsheep family:
beeminder-to-sqlite by Ben Congdon saves your goals and data points from Beeminder.
goodreads-to-sqlite by Tobias Kunze imports your reading history from Goodreads.
pinboard-to-sqlite by Jacob Kaplan-Moss saves your bookmarks from Pinboard.
todoist-to-sqlite by Ben Congdon saves your tasks and projects from Todoist.
parkrun-to-sqlite by Mark Woodbridge imports your parkruns.
If you want to see a demo of my own personal Dogsheep instance in action, take a look at the talk I gave about the project at PyCon AU 2020:
I used this Google Doc as a handout for the session, with links, notes and the Q&A.
Dogsheep Beta
I finally got dogsheep-beta working a few weeks ago. It’s the search engine that ties everything else together, and it works by building a single SQLite table with a search index built against copies of data pulled from all of the other sources.
It uses YAML configuration to specify queries that should be run against each data source to build the index - extracting out titles, timestamps and searchable text for each record.
The YAML can also define SQL to be used to load extra details about search results in order to feed variables to a template, and those templates can then be embedded in the YAML file as well. This means you can use Dogsheep Beta to quickly define custom multi-source search engines for any kind of content that you’ve previously pulled into a SQLite database.
It may even be useful for things other than personal search engines! I should really get a live demo up of it running somewhere that’s not full of my own personal data.
In the meantime, here’s a screenshot of my personal Dogsheep Beta instance showing a search for #dogfest that returns both tweets and Swarm checkins:
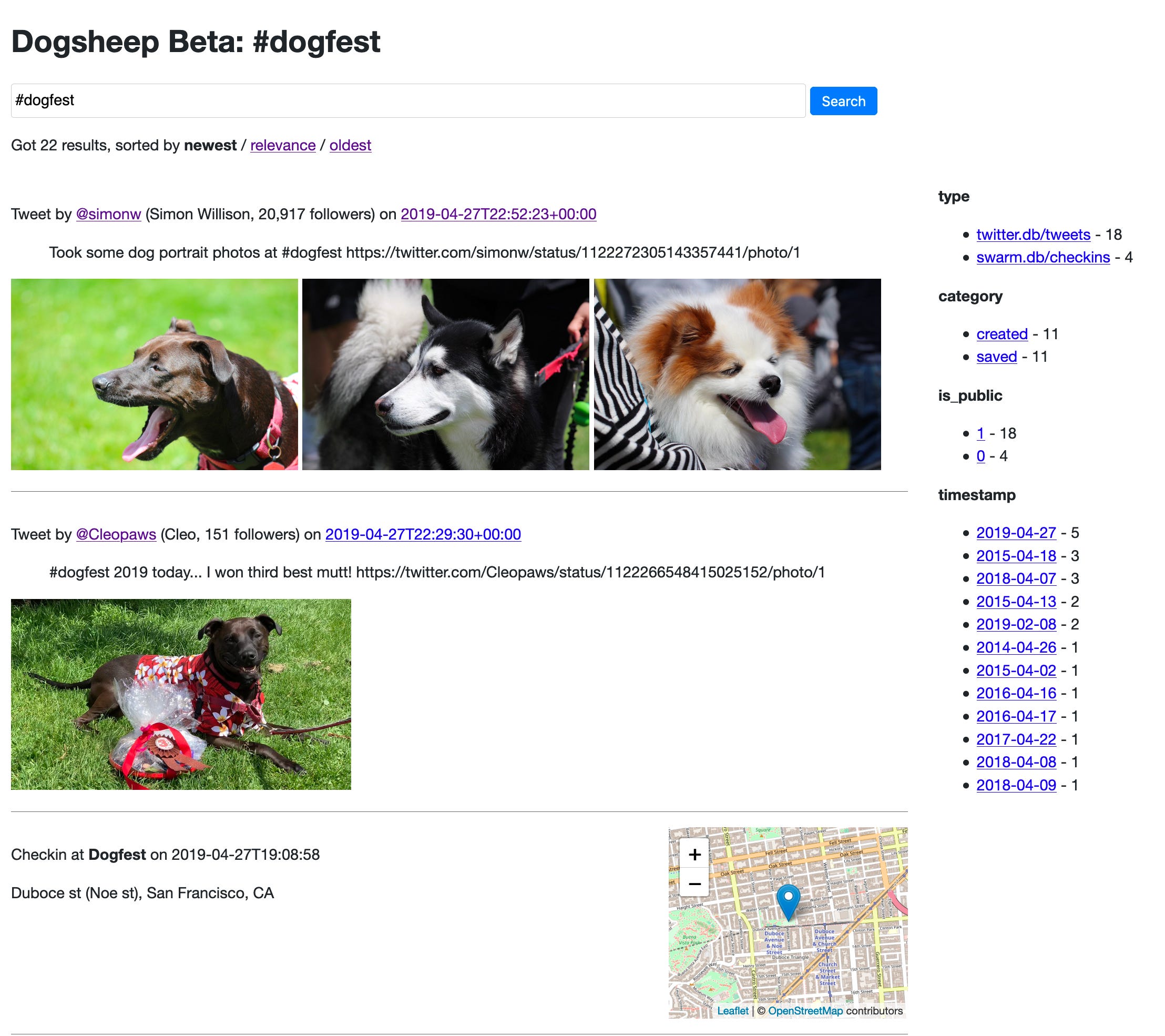
I released dogsheep-beta 0.9 at the weekend, upgraded to use the new datasette.client internal API request mechanism added in Datasette 0.50.
Datasette 1.0 API changes
I continue to work towards a Datasette 1.0 release. Datasette is pretty stable at the moment, but for 1.0 I want to be able to make a promise that plugins built against Datasette and external code written against Datasette’s JSON API will continue to work without changes until a 2.0 release that breaks backwards-compatibility: and with any luck I hope to stay in the 1.x series for as long as possible.
Datasette’s default JSON API at the moment isn’t quite right. When I work with it myself I almost always find myself opting for the ?_shape=array option - compare the following:
Default: covid-19.datasettes.com/covid/ny_times_us_counties.json
shape=array: covid-19.datasettes.com/covid/ny_times_us_counties.json?_shape=array
I’m reconsidering the default design at the moment in #782: Redesign default JSON format in preparation for Datasette 1.0. This is one of the most significant remaining tasks before a 1.0 release, so I want to be sure to get it right!
I’m experimenting with the new default shape in a plugin called datasette-json-preview, which adds a new .json-preview extension showing what I’m thinking about. You can try that out at https://latest-with-plugins.datasette.io/fixtures/facetable.json-preview - that’s a demo Datasette instance I run which installs as many plugins as possible in order to see what happens when they all run inside the same instance.
I am very keen to get feedback and suggestions on the JSON redesign. Please post any comments you might have on the issue.
Plugin of the week: datasette-cluster-map
datasette-cluster-map is the first Datasette plugin I released, and remains one of my favourites.
Once installed, it quietly checks each table to see if it has latitude and longitude columns. If it does, the plugin triggers, loads up a Leaflet map and attempts to render all of the rows with a latitude and longitude on a map.
It’s using Leaflet.markercluster under the hood, which in my experienc will quite happily display hundreds of thousands of clustered markers on a single page.
Here’s my favorite demo: a table of 33,000 power plants around the world using data maintained by the World Resources Institute. You can show them all on one map, or you can use Datasette facets to filter down to e.g. the 429 hydro plants in France:

I find myself using this plugin constantly - any time I come across data with latitude and longitude columns I’ll render it on a map, and often I’ll spot interesting anomolies - like the fact that the island of Corsica in the Mediterranean remains a region of France and has 7 Hydro power plants, as shown in the image above.
This also illustrates a pattern that I’m keen on exploring more: Datasette plugins which detect something interesting about the data that is being displayed and automatically offer additional ways to explore and visualize it. datasette-cluster-map is still the best example of this, but other examples include datasette-render-binary (tries to detect the format of binary data) and datasette-leaflet-geojson (spots GeoJSON values and renders them as a map).
Join the conversation
More newsletter next week, but in the meantime I’d love to hear from you on Twitter (I’m @simonw) or in the Datasette GitHub Discussions. Thanks for reading!