It’s been a while since the last edition of this newsletter, so plenty to cover today - starting with what’s new in Datasette and sqlite-utils, and then introducing a new Datasette-like tool aimed at Django + PostgreSQL developers called Django SQL Dashboard.
Datasette 0.55 added support for cross-database SQL queries: you can now start Datasette with the new “--crossdb” option which enables cross-database joins! More details in the documentation or you can try out an example cross-database query here.
0.56 was mainly small bug fixes and documentation improvements, though it did also introduce a handle you can drag to resize the SQL editor.
0.57 brought a critical security fix - if you have any Datasette instances running on the public web you should upgrade to a version higher than this (or 0.56.1 which applies the same fix to 0.56) as soon as possible.
It also fixed a long-standing issue where SQL errors were displayed without letting you edit your original SQL, and added mechanisms for selectively showing and hiding columns on a table page (“?_col=” and “?_nocol”).
0.58 added Unix domain socket support, useful for people running Datasette behind an Apache or NGINX proxy server. It also added two new plugin hooks and a significant performance boost for faceting - all of which are covered in detail in the Datasette 0.58 annotated release notes.
Datasette’s close companion is sqlite-utils - a combination CLI tool and Python library for creating and manipulating SQLite databases.
sqlite-utils gained two key new features this year.
sqlite-utils memory is a new command that lets you pipe JSON and CSV data directly into a temporary, in-memory SQLite database, execute a SQL query that filters or joins that data, then returns the results as tabular, CSV or JSON output.
It turns sqlite-utils into an ad-hoc querying tool that works against all sorts of data, and can be used to combine data from different sources - effectively running joins between JSON, CSV and other data sources.
I recorded a YouTube video showing the new tool in action:
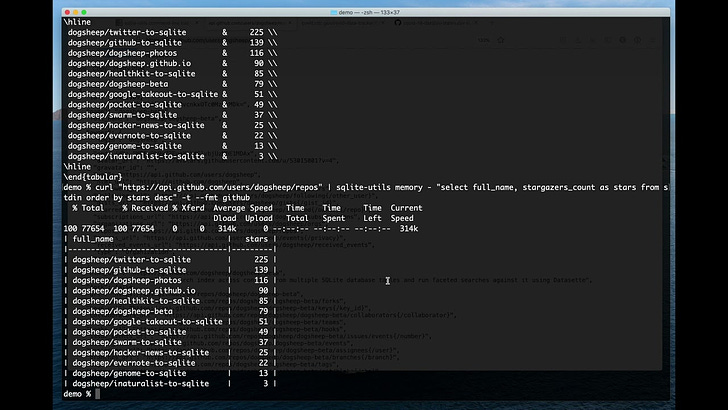
Here’s an example that fetches JSON from the GitHub API, executes a SQL query to select three columns and sort by the number of stars, then outputs the result to the console as CSV:
$ curl -s 'https://api.github.com/users/dogsheep/repos' \
| sqlite-utils memory - '
select full_name, forks_count, stargazers_count as stars
from stdin order by stars desc limit 3
' --csv
full_name,forks_count,stars
dogsheep/twitter-to-sqlite,12,225
dogsheep/github-to-sqlite,14,139
dogsheep/dogsheep-photos,5,116
I wrote more about this in Joining CSV and JSON data with an in-memory SQLite database.
The sqlite-utils convert command is the other big new feature: it lets you apply a conversion function written in Python to every value in a column in your SQLite database.
Here’s how to remove commas from a column with 123,456 style numbers:
sqlite-utils convert states.db states count \
'value.replace(",", "")'
And this will split a “location” column into two separate “latitude” and “longitude” columns (using the --multi option):
sqlite-utils convert data.db places location '
latitude, longitude = value.split(",")
return {
"latitude": float(latitude),
"longitude": float(longitude),
}' --multi
Read Apply conversion functions to data in SQLite columns with the sqlite-utils CLI tool for more.
I spent the first few months of the year mainly not working on Datasette at all: I joined the team running VaccinateCA / Vaccinate The States to build a Django application to help crowdsource information about places that people could go to get vaccinated against COVID-19 in the USA.
My first order of business was to help replace their Airtable infrastructure - which was rapidly reaching the size limits of what could be kept in Airtable - with a Django equivalent.
Since a major benefit of building on Airtable was its ad-hoc reporting abilities, I found myself really needing something similar to Datasette that could work against a PostgreSQL database.
So I built exactly that: Django SQL Dashboard - an open source package that adds a Datasette-like querying interface to a Django+PostgreSQL project, protected by the Django authentication layer.
I recorded this video with a demo of the project:
Lots more detail in the Django SQL Dashboard launch announcement.
I’m still deciding if and when to bring the lessons from that project back into Datasette itself - having Datasette work against PostgreSQL in addition to SQLite would open up a huge new set of possibilities for the project, and my work on Django SQL Dashboard has helped me start to scope out how much work it would be to make that a reality.
If you’re interested in reading more about my work at VaccinateCA I’ve imported my writing from my internal blog at the organization into my regular blog - you can find that series of posts here: simonwillison.net/series/vaccinateca
I decided to check how many new Datasette plugins I’ve released since the last newsletter on January 26th. The answer turned out to be seven! Here’s the query I used:
select
repos.full_name,
tag_name,
min(releases.created_at) as launched_at
from
releases
join repos on releases.repo = repos.id
where
repos.full_name like 'simonw/datasette-%'
and repos.full_name not in (
-- These are older but the first tagged release was this year
'simonw/datasette-jellyfish',
'simonw/datasette-haversine'
)
group by
repo
having
launched_at > '2021-01-26'
order by
launched_at
Run that here.
datasette-tiles is a plugin for serving map tiles directly out of a SQLite database, using the MBTiles standard for bundling tiles in a DB file.
datasette-basemap is a related plugin that bundles the first four layers of tiles from OpenStreetMap in a SQLite database file which can be installed in a place where Datasette can find it using “pip install datasette-basemap”.
Here’s a demo of the plugin, or you can browse the underlying database of tile images.
I wrote more about these plugins in Serving map tiles from SQLite with MBTiles and datasette-tiles.
datasette-block is a plugin that lets you block all access to specific path prefixes within Datasette. You probably don’t need this one!
datasette-placekey adds SQL functions for working with the placekey mechanism for creating identifiers for locations. I built this for some analysis at VaccinateCA.
datasette-remote-metadata lets you define your Datasette metadata in an external file and have Datasette fetch it on-demand while it is running. This is useful for if you have a large (1GB+) database running somewhere like Cloud Run where deploying new metadata can take several minutes - with the plugin you can edit the remote file and have the changes go live a few seconds later.
I built this as part of working with Stanford’s Big Local News to help launch the Stanford School Enrollment Project, which makes available detailed school enrollment figures for schools and districts across the USA from this year back to 2015.
datasette-pyinstrument adds the ability to add ?_pyinstrument=1 to any Datasette URL in order to see the output of a profile run while constructing the page.
datasette-query-links is a highly experimental plugin which looks out for SQL queries that return strings that are themselves valid SQL queries, and turns those strings into links that will execute the SQL. I thought this was a neat and unique idea, until I found out that PostgreSQL already has a version of this as a built in feature called \gexec!
I’ve decided to try and get this newsletter back onto a roughly monthly cadence. In the meantime, I suggest keeping an eye on the official Datasette website at datasette.io - you can even subscribe to its Atom feeds!
And a reminder: I’m still running Datasette Office Hours every Friday, so if you’d like to have a 25 minute video chat with me about Datasette to talk about things you’re working on or provide feedback on the project, sign up for a slot!